最近开始阅读Structure of Interpretation of Computer Science即计算机程序的构造与解释这本书。该书中使用的是Scheme作为Lisp的方言。 在此之前华盛顿大学的《程序设计语言》这门课的PartB中,我使用的Lisp方言是Racket,配合DrRacket作为IDE使用。因为最近一直在配置vim,这一次打算使用vim作为主力开发环境。
Unescaped left brace in regex is illegal here in regex; marked by <-- HERE in m/^\@strong{ <-- HERE (.*)}$/ at /home/guest/qemu/scripts/texi2pod.pl line 320.
make: *** [Makefile:474:qemu.1] 错误 255。
该错误是由于perl版本更新后正则表达式语法的变动造成的,直接修改安装脚本的/home/chenzhihao/qemu/scripts/texi2pod.pl line 320,将{改成 \{即可;
# Start the CPU: switch to 32-bit protected mode, jump into C. # The BIOS loads this code from the first sector of the hard disk into # memory at physical address 0x7c00and starts executing in real mode # with %cs=0 %ip=7c00. # boot.S 主要将CPU切换至32位保护模式,并且跳转进入C代码
# Set up the important data segment registers (DS, ES, SS). 设置重要的段寄存器为0 xorw %ax,%ax # Segment number zero movw %ax,%ds # -> Data Segment movw %ax,%es # -> Extra Segment movw %ax,%ss # -> Stack Segment
# Enable A20: # For backwards compatibility with the earliest PCs, physical # address line 20 is tied low, so that addresses higher than # 1MB wrap around to zero by default. This code undoes this. # 开启A20: # A20的介绍已经给出,不再赘述。 seta20.1: inb $0x64,%al # Wait for not busy 等待缓冲区可用 testb $0x2,%al # Test for bit1 # if bit1 = 1 then buffer is full jnz seta20.1
movb $0xd1,%al # 0xd1 -> port 0x64 outb %al,$0x64 # Prepare to write output port 准备写入输出端口
seta20.2: inb $0x64,%al # Wait for not busy 等待缓冲区可用 testb $0x2,%al jnz seta20.2 # The same as above 同上
# Switch from real to protected mode, using a bootstrap GDT # andsegment translation that makes virtual addresses # identical to their physical addresses, so that the # effective memory map does not change during the switch. lgdt gdtdesc # Load gdt size/base to gdtr 设置全局描述符表 movl %cr0, %eax # Control register 0 # bit0 is protected enable bit # 读取控制寄存器0的值,其Bit0为允许保护模式位 orl $CR0_PE_ON, %eax # Set PE 将允许保护模式位置1 movl %eax, %cr0 # Update Control register 0 设置控制寄存器0
# Jump to next instruction, but in32-bit code segment. # Switches processor into32-bit mode. ljmp $PROT_MODE_CSEG, $protcseg # 通过ljmp指令(跳转至下一条指令)进入保护模式
.code32 # Assemble for 32-bit mode 指导生成32位汇编代码 protcseg: # Set up the protected-mode data segment registers 设置保护模式的数据段寄存器 movw $PROT_MODE_DSEG, %ax # Our data segment selector movw %ax, %ds # -> DS: Data Segment movw %ax, %es # -> ES: Extra Segment movw %ax, %fs # -> FS movw %ax, %gs # -> GS movw %ax, %ss # -> SS: Stack Segment
# Set up the stack pointer andcallinto C. 设置栈指针并且调用C movl $start, %esp # Stack has the opposite extension direction than Code # 注意栈的延伸方向和代码段相反 call bootmain #调用main.c中的bootmain函数
# If bootmain returns (it shouldn't), loop. spin: jmp spin # Bootstrap GDT 引导GDT .p2align 2 # force 4 byte alignment gdt: SEG_NULL # null seg 默认第一个段描述符为空 SEG(STA_X|STA_R, 0x0, 0xffffffff) # code seg 设置代码段描述符 SEG(STA_W, 0x0, 0xffffffff) # data seg 设置数据段描述符 # 关于SEG宏可以参考mmu.h gdtdesc: # 用于设置全局段描述符寄存器 .word 0x17 # sizeof(gdt) - 1 # Size of gdt .long gdt # address gdt # Base address of gdt
为了理解main.c,需要如下的知识储备。
ELF文件格式
可执行和可链接格式(Executable and Linkable Format)是一种用于二进制文件、可执行文件、目标代码、共享库和核心转储格式文件。
磁盘是电脑主要的存储媒介。磁盘是由盘片构成的。每个盘片有两面或者称为表面,表面覆盖着磁性记录材料。盘片中央有一个可以旋转的主轴,它使得盘片以固定的旋转速率旋转,通常是5400-15000转每分钟(Revolution Per Minute)。磁盘通常包含一个或多个这样的盘片,并封装在一个密封的容器内。
/********************************************************************** * This a dirt simple boot loader, whose sole job is to boot * an ELF kernel image from the first IDE hard disk. * * DISK LAYOUT * * This program(boot.S and main.c) is the bootloader. It should * be stored in the first sector of the disk. * * * The 2nd sector onward holds the kernel image. * * * The kernel image must be in ELF format. * * BOOT UP STEPS * * when the CPU boots it loads the BIOS into memory and executes it * * * the BIOS intializes devices, sets of the interrupt routines, and * reads the first sector of the boot device(e.g., hard-drive) * into memory and jumps to it. * * * Assuming this boot loader is stored in the first sector of the * hard-drive, this code takes over... * * * control starts in boot.S -- which sets up protected mode, * and a stack so C code then run, then calls bootmain() * * * bootmain() in this file takes over, reads in the kernel and jumps to it. **********************************************************************/
// read 1st page off disk 从磁盘上读取第一页 readseg((uint32_t)ELFHDR, SECTSIZE * 8, 0);
// is this a valid ELF? 通过ELF魔数确认ELF有效 if (ELFHDR->e_magic != ELF_MAGIC) goto bad;
// load each program segment (ignores ph flags) 读取各个段 ph = (struct Proghdr *)((uint8_t *)ELFHDR + ELFHDR->e_phoff); // 程序头部表的起始地址 eph = ph + ELFHDR->e_phnum; // 程序头部表的结束地址 for (; ph < eph; ph++) // p_pa is the load address of this segment (as well // as the physical address) // p_pa是加载地址也是物理地址 readseg(ph->p_pa, ph->p_memsz, ph->p_offset);
// call the entry point from the ELF header 从ELF头调用程序入口 // note: does not return! ((void (*)(void))(ELFHDR->e_entry))();
bad: // stops simulation and breaks into the debug console outw(0x8A00, 0x8A00); outw(0x8A00, 0x8E00); while (1) /* do nothing */; }
// Read 'count' bytes at 'offset' from kernel into physical address 'pa'. // 从内核的offset处读取count个字节到物理地址pa处 // Might copy more than asked 可能会读取超过count个(扇区对齐) voidreadseg(uint32_t pa, uint32_t count, uint32_t offset){ uint32_t end_pa;
end_pa = pa + count; // 结束物理地址
// round down to sector boundary 对齐到扇区 pa &= ~(SECTSIZE - 1);
// translate from bytes to sectors, and kernel starts at sector 1 offset = (offset / SECTSIZE) + 1; // 算出扇区数 注意扇区从1开始(0为引导扇区)
// If this is too slow, we could read lots of sectors at a time. // We'd write more to memory than asked, but it doesn't matter -- // we load in increasing order. // 在实际中往往将多个扇区一起读出以提高效率。 while (pa < end_pa) { // Since we haven't enabled paging yet and we're using // an identity segment mapping (see boot.S), we can // use physical addresses directly. This won't be the // case once JOS enables the MMU. // 考虑到没有开启分页以及boot.S中使用了一一对应的映射规则, // 加载地址和物理地址是一致的。 readsect((uint8_t *)pa, offset); pa += SECTSIZE; offset++; } }
voidwaitdisk(void){ // wait for disk reaady 等待磁盘准备完毕。 while ((inb(0x1F7) & 0xC0) != 0x40) /* do nothing */; }
voidreadsect(void *dst, uint32_t offset){ // wait for disk to be ready waitdisk();
outb(0x1F2, 1); // count = 1 0x1F2 Disk 0 sector count // Read one sector each time outb(0x1F3, offset); // Disk 0 sector number (CHS Mode) // First sector's number outb(0x1F4, offset >> 8); // Cylinder low (CHS Mode) outb(0x1F5, offset >> 16); // Cylinder high (CHS Mode) // Cylinder number outb(0x1F6, (offset >> 24) | 0xE0); // Disk 0 drive/head // MASK 11100000 // Drive/Head Register: bit 7 and bit 5 should be set to 1 // Bit6: 1 LBA mode, 0 CHS mode outb(0x1F7, 0x20); // cmd 0x20 - read sectors /*20H Read sector with retry. NB: 21H = read sector without retry. For this command you have to load the complete circus of cylinder/head/sector first. When the command completes (DRQ goes active) you can read 256 words (16-bits) from the disk's data register. */
// wait for disk to be ready waitdisk();
// read a sector insl(0x1F0, dst, SECTSIZE / 4); // Data register: data exchange with 8/16 bits // insl port addr cnt: read cnt dwords from the input port // specified by port into the supplied output array addr. // dword: 4 bytes = 16 bits }
staticstructCommandcommands[] = { { "help", "Display this list of commands", mon_help }, { "kerninfo", "Display information about the kernel", mon_kerninfo }, { "backtrace", "Display information about the stack frames", mon_backtrace }, };
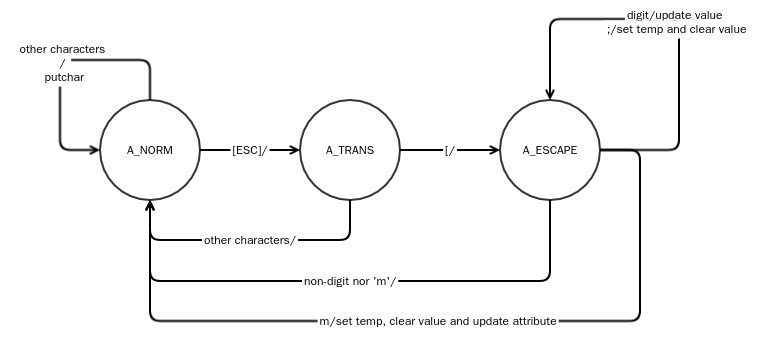
staticvoidattribute_punch(int ch, int *cnt){ staticint value = 0; // value staticint state = A_NORM; // current state staticint temp = 0x0000, attribute = 0x0000; // temp attribute, current attribute
switch (state) { // state machine case A_NORM: if (ch == 0x1B) { // [ESC] state = A_TRANS; // transfer from A_NORM to A_TRANS } else { cputchar((attribute & 0xFF00) | ch); // put character with attribute *cnt++; } break; case A_TRANS: if (ch == '[') { // [ state = A_ESCAPE; // transfer from A_TRANS to A_ESCAPE } else { state = A_NORM; // transfer from A_TRANS to A_NORM } break; case A_ESCAPE: if (ch >= '0' && ch <= '9') { // digit - update value value = value * 10 + ch - '0'; } elseif (ch == ';' || ch == 'm') { // ; or m set temp and clear value if (value == 0) { temp = colormap[0]; } elseif (value == 5) { temp |= 0x8000; } elseif (value >= 30 && value <= 38) { temp |= colormap[value - 30] & 0x0700; // look up in color map } elseif (value >= 40 && value <= 48) { temp |= colormap[value - 40] & 0x7000; // avoid complex cases } value = 0; if (ch == 'm') { // m needed extra work - update attribute attribute = temp; temp = 0x0000; state = A_NORM; // transfer from A_ESCAPE to A_NORM } } else { // non_digit nor m state = A_NORM; // transfer from A_ESCAPE to A_NORM } break; } }
intvcprintf(constchar *fmt, va_list ap){ int cnt = 0;
// vprintfmt((void*)putch, &cnt, fmt, ap); // use attribute_punch rather than punch vprintfmt((void *)attribute_punch, &cnt, fmt, ap); return cnt; }
for (a = 0 ; a < N ; a += 8) { for (b = 0 ; b < M ; b += 8) { for (c = b ; c < b + 8 ; ++c) { for (d = a + c - b ; d >= a ; --d) { B[c][d] = A[d][c]; } for (d = a + c - b + 1 ; d < a + 8 ; ++d) { B[c][d] = A[d][c]; } } } }
for (a = 0 ; a < M ; a += 8) { for (b = 0 ; b < N ; b += 8) { for (c = a ; c < a + 4 ; ++c) { for (d = b + c - a ; d >= b ; -- d) { B[c][d] = A[d][c]; } for (d = b + c - a + 1; d < b + 4 ; ++d) { B[c][d] = A[d][c]; } }
for (c = a + 4; c < a + 8 ; ++c) { for (d = b + c - a ; d >= b + 4 ; --d) { B[c][d] = A[d][c]; } for (d = b + c - a + 1 ; d < b + 8 ; ++d) { B[c][d] = A[d][c]; } }
for (a = 0 ; a < N ; a += 16) { for (b = 0 ; b < M ; b += 16) { for (c = b ; (c < b + 16) && (c < M) ; ++c) { for (d = a ; (d < a + 16) && (d < N) ; ++d) { B[c][d] = A[d][c]; } } } }
实际测试的缓存不命中数是1847次。
实验结果
自动评分脚本给出的输出如下:
1 2 3 4 5 6 7
Cache Lab summary: Points Max pts Misses Csim correctness 27.0 27 Trans perf 32x32 8.0 8 287 Trans perf 64x64 8.0 8 1219 Trans perf 61x67 10.0 10 1847 Total points 53.0 53
voideval(char *cmdline) { char * argv[MAXARGS]; char buf[MAXLINE]; int bg; /* if run in background */ pid_t pid;
sigset_t mask_all, mask_chld, prev_chld;
/*initialize signal sets*/ Sigfillset(&mask_all); Sigemptyset(&mask_chld); Sigaddset(&mask_chld, SIGCHLD);
strcpy(buf, cmdline); bg = parseline(buf, argv); /* parse the command line */ if (argv[0] == NULL) { return; } /* handles if there is empty input */
if (!builtin_cmd(argv)) { /* if the command line is builtin command */ Sigprocmask(SIG_BLOCK, &mask_chld, &prev_chld); /* block SIGCHLD to avoid potential race between addjob and deletejob */ if ((pid = Fork()) == 0) { Setpgid(0, 0); /* give the child process a new group id to handle SIGINT correctly */ Sigprocmask(SIG_SETMASK, &prev_chld, NULL); /* unblock SIGCHLD */ Execve(argv[0], argv, environ); } Sigprocmask(SIG_BLOCK, &mask_all, NULL); /* mask all signals to avoid potential races */ addjob(jobs, pid, bg + 1, cmdline); /* add job to joblist */ Sigprocmask(SIG_SETMASK, &prev_chld, NULL); if (!bg) { /* if the process should be exeuted in foreground */ waitfg(pid); /* fg wait explictly */ } else { printf("[%d] (%d) %s", pid2jid(pid), pid, cmdline); /* bg print message*/ } }
return; }
intbuiltin_cmd(char **argv) { /* handles the builtin command in current context */ if (!strcmp(argv[0], "quit")) { exit(0); /* quit: exit directly*/ } if (!strcmp(argv[0], "jobs")) { listjobs(jobs); /* jobs: print the current job list */ return1; } if (!strcmp(argv[0], "bg") || !strcmp(argv[0], "fg")) { do_bgfg(argv); /* bg|fg: handles in function do_bgfg */ return1; } if (!strcmp(argv[0], "&")) { return1; /* returns 1 for empty & */ } return0; /* not a builtin command */ }
voiddo_bgfg(char **argv) { int number = 0; /* used to store the converted number */ char * ptr = argv[1]; /* get the pointer to argument 1 */ char * endptr = NULL; /* used for error handling */ structjob_t * job = NULL;/* used to store job pointer */ if (!argv[1]) { /* returns if missing argument */ printf("%s command requires PID or %%jobid argument\n", argv[0]); return; } if (*ptr == '%') { /* if argument 1 is job ID */ ptr++; /* adjust pointer */ number = strtol(ptr, &endptr, 10); if (ptr == endptr) { /* handles convert error */ printf("%s: argument must be a PID or %%jobid\n", argv[0]); return; } job = getjobjid(jobs, number); /* get the job */ if (!job) {/* handles if there is no such job */ printf("%%%d: No such job\n", number); return; } } else {/* if argument 1 is pid */ number = strtol(ptr, &endptr, 10); if (ptr == endptr) { /* handles convert error */ printf("%s: argument must be a PID or %%jobid\n", argv[0]); return; } job = getjobpid(jobs, (pid_t)number); /* get the job */ if (!job) {/* handles if there is no such job */ printf("(%d): No such process\n", number); return; } } /* change process state and update the job list*/ if (!strcmp(argv[0], "bg")) { /*bg: turns ST to BG, send SIGCONT */ if(job->state == ST) { Kill(-(job->pid), SIGCONT); printf("[%d] (%d) %s", job->jid, job->pid, job->cmdline); job->state = BG; } } elseif (!strcmp(argv[0], "fg")) {/* fg: turns ST/BG to FG, sent SIGCONT */ if(job->state == ST) { Kill(-(job->pid), SIGCONT); job->state = BG; } if(job->state == BG) { job->state = FG; waitfg(job->pid); } } return; }
voidwaitfg(pid_t pid) { while(fgpid(jobs)) { /* handles all zombie processes in signal handler */ sleep(0.01); /* busy loop only */ } return; }
voidsigchld_handler(int sig) { int olderrno = errno; /* store old errno */ int status; /* used to trace pid's status */ sigset_t mask_all, prev_all; pid_t pid;
Sigfillset(&mask_all);
while((pid = Waitpid(-1, &status, WUNTRACED | WNOHANG)) > 0) { /* waitpid without waiting(WNOHANG) */ if (WIFSTOPPED(status) && (WSTOPSIG(status) == SIGTSTP || WSTOPSIG(status) == SIGSTOP)) { /* if the process is stopped */ structjob_t * job = getjobpid(jobs, pid); if (job && job->state != ST) { /* if the stop signal hasn't been catched */ printf("Job [%d] (%d) stopped by signal %d\n", pid2jid(pid), pid, WSTOPSIG(status)); structjob_t * stpjob = getjobpid(jobs, pid); stpjob->state = ST;/* handles here */ } } if (WIFSIGNALED(status) && WTERMSIG(status) == SIGINT) { /* it the terminate signal hasn't been catched */ structjob_t * job = getjobpid(jobs, pid); if (job) { printf("Job [%d] (%d) terminated by signal %d\n", pid2jid(pid), pid, WTERMSIG(status)); /* handles here */ } } if (WIFEXITED(status) || WIFSIGNALED(status)) { Sigprocmask(SIG_BLOCK, &mask_all, &prev_all); deletejob(jobs, pid); Sigprocmask(SIG_SETMASK, &prev_all, NULL); }/* remove the job in job list accordingly */ } errno = olderrno; return; }
voidsigint_handler(int sig) { int olderrno = errno; /* store old errno */ sigset_t mask_all, prev_all; Sigfillset(&mask_all); Sigprocmask(SIG_BLOCK, &mask_all, &prev_all); /* block all signal in case the race between SIGINT and SIGCHLD */
pid_t pid; pid = fgpid(jobs); Kill(-pid, SIGINT); /* kill processes in fg job's process group */
printf("Job [%d] (%d) terminated by signal %d\n", pid2jid(pid), pid, sig); /* print the message */
deletejob(jobs, pid); /* delete job in joblist */
Sigprocmask(SIG_SETMASK, &prev_all, NULL);
errno = olderrno; return; }
voidsigtstp_handler(int sig) { int olderrno = errno; /* store old errno */ sigset_t mask_all, prev_all; Sigfillset(&mask_all); Sigprocmask(SIG_BLOCK, &mask_all, &prev_all); /* block all signal in case the race between SIGTSTP and SIGCHLD */
pid_t pid; pid = fgpid(jobs); Kill(-pid, SIGTSTP); /* send SIGTSTP to fg job's process group */
printf("Job [%d] (%d) stopped by signal %d\n", pid2jid(pid), pid, sig); /* print the message */
structjob_t * stpjob = getjobpid(jobs, pid); stpjob->state = ST; /* modify the job list */
The core data structure deals with image representation. A pixel is a structasshownbelow: typedefstruct { unsignedshort red; /* R value */ unsignedshort green; /* G value */ unsignedshort blue; /* B value */ } pixel;
此外,为了简化起见,还定义了如下的宏:
1
#define RIDX(i,j,n) ((i)*(n)+(j))
旋转操作的朴素版本如下:
1 2 3 4 5 6 7
voidnaive_rotate(int dim, pixel *src, pixel *dst){ int i, j; for(i=0; i < dim; i++) for(j=0; j < dim; j++) dst[RIDX(dim-1-j,i,dim)] = src[RIDX(i,j,dim)]; return; }
平滑操作的朴素版本如下(辅助函数未列出):
1 2 3 4 5 6 7
voidnaive_smooth(int dim, pixel *src, pixel *dst){ int i, j; for(i=0; i < dim; i++) for(j=0; j < dim; j++) dst[RIDX(i,j,dim)] = avg(dim, i, j, src); /* Smooth the (i,j)th pixel */ return; }
voidblock_rotate(int dim, pixel * src, pixel * dst){ int i, j, k, l; int cst0 = dim - 1; for (i = 0 ; i < dim ; i += 8) { for (j = 0 ; j < dim ; j += 8) { for (k = i ; k < i + 8 ; k++) { for (l = j ; l < j + 8 ; l++) { dst[RIDX(cst0 - l, k, dim)] = src[RIDX(k, l, dim)]; } } } } }
Usage: ./csim-ref [-hv] -s <s> -E <E> -b <b> -t <tracefile> • -h: Optional help flag that prints usage info • -v: Optional verbose flag that displays trace info • -s <s>: Number of set index bits (S = 2 s is the number of sets) • -E <E>: Associativity (number of lines per set) • -b <b>: Number of block bits (B = 2 b is the block size) • -t <tracefile>: Name of the valgrind trace to replay
linux> ./csim-ref -v -s 4 -E 1 -b 4 -t traces/yi.trace L 10,1 miss M 20,1 miss hit L 22,1 hit S 18,1 hit L 110,1 miss eviction L 210,1 miss eviction M 12,1 miss eviction hit hits:4 misses:5 evictions:3
user@BlackDragon ~/C/B/buflab-handout> cat level0.txt|./hex2raw|./bufbomb -u BlackDragon Userid: BlackDragon Cookie: 0x3dde924c Type string:Smoke!: You called smoke() VALID NICE JOB! run with level1
voidfizz(int val) { if (val == cookie) { printf("Fizz!: You called fizz(0x%x)\n", val); validate(1); } else printf("Misfire: You called fizz(0x%x)\n", val); exit(0); }
user@BlackDragon ~/C/B/buflab-handout> gdb bufbomb GNU gdb (GDB) 7.12.1 Copyright (C) 2017 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty"for details. This GDB was configured as "x86_64-pc-linux-gnu". Type "show configuration"for configuration details. For bug reporting instructions, please see: <http://www.gnu.org/software/gdb/bugs/>. Find the GDB manual and other documentation resources online at: <http://www.gnu.org/software/gdb/documentation/>. For help, type"help". Type "apropos word" to search for commands related to "word"... Reading symbols from bufbomb...(no debugging symbols found)...done. (gdb) break getbuf Breakpoint 1 at 0x80491fa (gdb) run -u BlackDragon Starting program: /home/user/CSAPPLabs/BufferLab/buflab-handout/bufbomb -u BlackDragon Userid: BlackDragon Cookie: 0x3dde924c
user@BlackDragon ~/C/B/buflab-handout> cat level2.txt|./hex2raw|./bufbomb -u BlackDragon Userid: BlackDragon Cookie: 0x3dde924c Type string:Bang!: You set global_value to 0x3dde924c VALID NICE JOB!
user@BlackDragon ~/C/B/buflab-handout> cat level4.txt|./hex2raw -n|./bufbomb -u BlackDragon -n Userid: BlackDragon Cookie: 0x3dde924c Type string:KABOOM!: getbufn returned 0x3dde924c Keep going Type string:KABOOM!: getbufn returned 0x3dde924c Keep going Type string:KABOOM!: getbufn returned 0x3dde924c Keep going Type string:KABOOM!: getbufn returned 0x3dde924c Keep going Type string:KABOOM!: getbufn returned 0x3dde924c VALID NICE JOB!